if-else if-else문 : 조건문 중첩. 필요한 만큼 조합할 수 있고, 마지막은 else로 구성. else는 조건이 모두 거짓일 때 수행할 문장 실행
비교 연산자와 논리 연산자의 복합 : 비교 연산자 (>=, <=)와 논리곱 연산자 (&&) 사용
범위(range) 연산자 : 변수명 in 시작값..마지막값
if-else문 실습
if-else if문 실습
readLine()은 콘솔로부터 값을 읽어들이는 함수이다.
범위 연산자 사용. 80점 이상 89.9 이하로 80점과 89.9를 포함
when문 : 코틀린에 들어간 새로운 조건 처리 방식
인자가 없는 when
when (인자) {
인자에 일치하는 값 혹은 표현식 -> 수행할 문장
인자에 일치하는 범위 -> 수행할 문장
...
else -> 문장
}
when 문장 안에 들어갈 수 있는 조건 처리 방식
일치되는 여러 조건
함수의 반환값 사용
in 연산자와 범위 지정자 사용
is 키워드 사용
인자가 있는 when 실습
인자가 없는 when : 특정 인자에 제한하지 않고 다양한 조건을 구성
when {
조건[혹은 표현식] -> 실행문
...
}
위에 있는 when문은 인자가 있는 조건 처리 방식, 아래에 있는 when문은 인자가 없는 조건 처리 방식
for문
!!코틀린에서는 자바와 같은 세미콜론 표현식을 사용하지 않는다!!
for (요소 변수 in 컬렉션 혹은 범위) {
반복할 본문
}
for문 실습
위 for문은 홀수합이고, 아래 for문은 짝수합을 수행하는 문장이다.
while문 : 탈출문을 만들지 않으면 무한 루프를 도는 경우가 생김. 죽지 않는 프로그램을 만드는 경우, 데몬 프로그램의 경우 주로 사용.
while문 실습
factorial을 만드는 while문으로, 숫자를 점점 줄여나가면서 number 변수가 0이 되었을 경우 while문을 빠져나가게 된다.
do-while문 : while문의 조건식을 나중에 진행하는 것으로, do 본문에 있는 것을 실행한 후 while문의 조건식을 실행. while문의 조건식이 false일 경우 while 이후 문장을 실행
do-while문 실습
콘솔 창에서 값을 입력받은 후, do 본문의 내용을 실행한다.
do 본문의 내용을 전부 실행하면 while 조건식에 들어가게 되고, true면 do 본문으로 되돌아가고, false면 while 이후 문장을 실행한다. 여기서는 while 이후 문장이 따로 없기 때문에 입력 값으로 0이 들어오게 되면 do-while문이 끝나는 형식이다.
코틀린으로 when 조건 처리 방식을 처음 보았고, for문이 다른 언어와는 다른 형식으로 쓰이기 때문에 이를 주의해서 kotlin언어를 사용할 필요가 있다. 조건문과 반복문은 코드를 짤 때 정말 중요하게 자주 쓰이는 것이기 때문에 잘 알아둘 필요성이 있다.
fun d() = e() 에서 오류가 난 이유는, e()가 지역 함수이기 때문에 d() 함수 앞에 선언해주어야 오류 없이 사용가능하다.
main() 함수에서 e() 함수 호출에 실패한 이유는 e() 함수는 c() 함수에 정의되어있기 때문에 c의 블록 ({})을 벗어난 곳에서는 사용할 수 없다.
최상위 함수, 지역 함수, 전역 변수, 지역 변수 실습
가장 먼저 전역 변수를 읽어들여 데이터 영역에 전역 변수 공간을 만들고 값을 저장하고, main() 함수에 진입한다.
main() 함수에 진입하여 가장 먼저 만나는 식은 localFunc1() 함수 호출문이다.
localFunc1() 함수는 localFunc1을 출력하는 main() 함수 안에 선언된 함수로, main() 함수 밖에서는 사용할 수 없다.
따라서 userFunc() 함수에서 호출하게 되면 오류가 발생한다.
그 다음으로는 전역 변수 global의 값을 15로 바꾼다.
local1을 스택 영역에 저장하고나서, global 변수의 값을 출력하면 15가 나온다.
다음으로는 userFunc() 함수를 호출한다.
들어가면 global 변수의 값이 20으로 바뀐다. 전역 변수 global은 패키지 내 모든 global 변수에 영향을 주기 때문에 main()에서 사용했던 global 값도 똑같이 20인 것이다.
그리고 userFunc() 함수 내에서도 local1을 선언했는데, 이는 main() 함수 안에 선언된 변수와는 다른 변수이기 때문에 따로 또 스택에 저장이 되고, userFunc() 함수 내 local1 변수의 값이 20으로 저장이 된다.
userFunc() 함수 내에서 global 변수와 local1 변수를 출력하면 각각 20, 15가 출력된다.
userFunc() 함수 실행이 끝났기 때문에 스택에 저장되어 있던 userFunc() 함수의 local1 변수는 스택에서 빠지게 된다.
마지막으로 main() 함수에서 global 변수와 local1 변수는 각각 20과 10으로 출력된다.
global 변수는 아까 userFunc() 함수에서 바뀐 값에 영향을 받아 20이고, local1 변수는 지역 변수이기 때문에 main() 함수에서 정의한 것만 읽어들여, 계속 10의 값을 가지고 있다.
전역 변수를 쓰다보면 편하다는 것을 알 수 있다. 함수 매개변수로 넣는 대신 전역 변수를 사용하고 싶다는 생각을 하곤 했다. 하지만 전역 변수를 아무때나 사용하는 것은 위험할 수 있다. 함수 매개변수로 값을 전달해주게 되면 원래 값을 복사해서 다른 함수에서 사용하는 것이기 때문에 값이 임의로 바뀌는 일을 막을 수 있는 반면, 전역 변수로 선언하여 여러 함수에서 이를 사용하게 되면 원치 않는 일이 발생할 수 있기 때문에 조심히, 프로그램의 알고리즘을 충분히 고려한 후 사용하는 것이 좋다.
val nestedLambda: () -> () -> Unit = { {println("nested")} }
자료형을 추론할 수 있으면 선언부의 자료형을 생략할 수 있음
val greet = {println("Hello World!")} // 추론 가능
val squre = {x : Int -> x * x} // 선언 부분을 생략하려면 x의 자료형을 명시해야 함
val nestedLambda = { {println("nested")} } // 추론 가능 : Unit형
람다식 실습
람다식은 multi1처럼 람다식의 매개변수를 선언할 때 자료형도 함께 정의하여 써도 되고,
multi2처럼 람다식의 선언 자료형을 앞으로 빼도 된다.
반환 자료형이 없거나 매개변수가 하나 있을 때
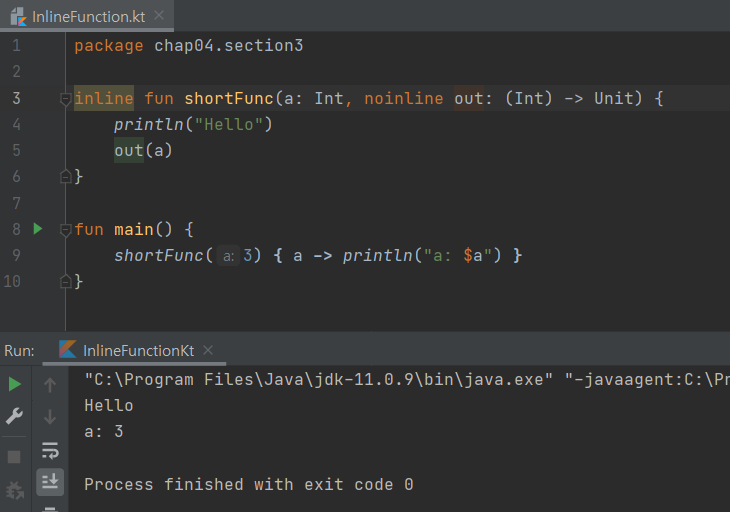
고차함수 실습
sum 함수는 자료형을 추론할 수 있기 때문에 자료형을 생략하고 함수를 간략하게 표현하여 보았다.
result2처럼 함수 안에 함수를 넣어 표현할 수 있다. 함수의 매개변수를 함수로 지정하여도 된다
함수의 반환값을 함수로 지정하여도 된다
매개변수에 람다식 함수를 이용한 고차 함수도 표현 가능하다.
첫 번째 인자는 람다식이고, 두 번째와 세 번째 인자는 람다식은 일반 정수 값 인자로 람다식 연산에 사용된다.
값에 의한 호출 : 함수가 인자로 전달될 경우
람다식 함수는 값으로 처리되어 그 즉시 함수가 수행된 후 값을 전달
값에 의한 호출 실습
main함수에서 lambda 함수를 호출하면 바로 람다식 함수가 즉시 실행된다.
lambda식이 호출되면 print문이 실행되고 true가 반환된다.
그리고 callByValue b에 true 값이 복사되어 print문이 실행되고 b가 또 반환된다.
그러면 result에 b가 들어가서 출력된다.
차이점은 람다식 이름으로 호출됐다는 것이다. 이름만 사용하게 되면, 람다식 자체가 매개변수에 복사되어 return에서 람다식 함수가 호출돼 실행된다. 따라서 필요할 때만 람다식이 작동한다.
위와 아래는 어디서 람다식이 호출되느냐가 다르다.
다름 함수의 참조에 의한 호출 : 람다식이 아닌 일반 함수를 또 다른 함수의 인자에서 호출하는 함수의 경우로, 두 개의 콜론기호(::)를 함수 이름 앞에 사용해 소괄호와 인자를 생략하고 사용하면 된다
매개변수 개수에 따라 람다식을 구성하는 방법
1. 매개변수가 없는 경우 : 매개변수가 없는 람다식 함수가 noParam함수의 매개변수 out으로 지정됨
fun main() {
noParam({"Hello World!"})
noParam{"Hello World!"}
}
fun noParam(out: () -> String) = println(out())
소괄호는 생략 가능
2. 매개변수가 한 개인 경우 : 매개변수가 하나 있는 람다식 함수가 oneParam함수의 매개변수 out으로 지정됨
fun main() {
oneParam({a -> "Hello World! $a"})
oneParam{a -> "Hello World! $a"}
oneParam{"Hello World $it"}
}
fun oneParam(out: (String) -> String) {
println(out("OneParam"))
}
소괄호 생략가능하고, it로 대체 가능
3. 매개변수가 두 개 이상인 경우 : 매개변수가 두 개 있는 람다식 함수가 moreParam함수의 매개변수로 지정됨
fun main() {
moreParam{a, b -> "Hello World! $a $b"}
}
fun moreParam(out: (String, String) -> String) {
println(out("OneParam", "TwoParam"))
}
매개변수명 생략 불가, 매개변수를 생략하는 경우 _를 사용하여 생략함을 표현한다.
4. 일반 매개변수와 람다식 매개변수를 같이 사용
fun main() {
withArgs("Arg1", "Arg2", {a, b -> "Hello World! $a $b"})
withArgs("Arg1", "Arg2") {a, b -> "Hello World! $a $b"}
}
fun withArgs(a: String, b: String, out: (String, String) -> String) {
println(out(a, b))
}
withArgs()의 마지막 인자가 람다식인 경우 소괄호 바깥으로 분리 가능
5. 두 개의 람다식을 가진 함수의 사용
fun main() {
twoLambda({a, b -> "First $a $b"}, {"Second $it"})
twoLambda({a, b -> "First $a $b"}) {"Second $it"}
}
fun twoLambda(first: (String, String) -> String, second: (String) -> String) {
println(first("OneParam", "TwoParam"))
println(second("OneParam"))
}
람다식, 고차 함수를 사용해 구성 (함수 자체를 함수 안에 넣을 수 있고, 함수 자체를 반환할 수도 있음)
순수 함수
사용 이유
프로그램을 모듈화 해 디버깅하거나 테스트가 쉬움
간략한 표현식을 사용해 생산성이 높음
람다식과 고차함수를 사용하면서 다양한 함수 조합을 사용할 수 있음
순수 함수 (pure function)
부작용 (side-effect)이 없는 함수
동일한 입력 인자에 대해서는 항상 같은 결과 출력 혹은 반환
값 예측 가능 -> 결정적 (deterministic)
순수 함수의 조건
같은 인자에 대하여 항상 같은 값 반환
함수 외부의 어떤 상태도 바꾸지 않음
안되는 경우 : 외부의 객체, 외부의 변수 사용하는 경우 등
순수 함수를 사용하는 이유
입력과 내용을 분리하고 모듈화 하므로 재사용성이 높아져, 여러 가지 함수들과 조합해도 부작용이 없음
특정 상태에 영향을 주지 않으므로 병행 작업 시 안전하게 작동 가능
함수의 값을 추적하고 예측할 수 있기 때문에 테스트, 디버깅 등 유리
함수형 프로그래밍에 적용 가능
함수를 매개변수, 인자에 혹은 반환값에 적용 (고차 함수)
함수를 변수나 데이터 구조에 저장
유연성 증가 (프로그램 읽기에는 복잡함이 있을 수 있음)
fun sum(a: Int, b: Int): Int {
return a + b // 동일한 인자인 a, b를 입력 받아 항상 a + b를 출력(부작용이 없음)
}
람다식
익명 함수의 하나의 형태로 이름 없이 사용 및 실행 가능
람다 대수 (Lambda calculus)로 부터 유래
고차 함수에서 인자로 넘기거나 결과값으로 반환 등 가능
{ x, y -> x + y } // 람다식의 예 (이름이 없는 함수 형태)
일급 객체 (First Class Citizen)
함수의 인자로 전달 가능
함수의 반환값에 사용 가능
변수에 담을 수 있음
코틀린에서 함수는 1급 객체로 다룸 (= 1급 함수)
고차 함수 (high-order function)
출처 : 코틀린 프로그래밍 기본1/2 (함수편) 3-3 함수형 프로그래밍 패러다임! (1) 참고자료
fun main() {
println(highFunc({ x, y -> x + y }, 10, 20)) // 람다식 함수를 인자로 넘김
}
fun highFunc(sum: (Int, Int) -> Int, a: Int, b: Int): Int = sum(a, b) // sum 매개변수는 함수
고차함수 실습
람다 함수를 맨 마지막 매개변수로 지정하였을 경우에는 인자 밖으로 빼내서 작성하여도 상관없다.
고참 함수, 람다 함수는 프로젝트를 할 때 많이 사용된다. 간략하고 생산성이 높아서 자주 사용되기 때문에 정확히 알아두는 것이 좋다.
함수 : 입력값이 들어오면 함수 안에서 처리 후 값을 반환하는 것. 입력, 반환은 필수 아님
fun 함수 이름([변수 이름: 자료형, 변수 이름: 자료형..]): [반환값의 자료형] {
표현식...
[return 반환값]
}
하나의 함수를 다양하게 표현할 수 있다.
// 일반적인 함수의 모습
fun sum(a: Int, b: Int): Int {
return a + b
}
// 간략화된 함수
fun sum(a: Int, b: Int): Int = a + b
// 반환 자료형 생략
fun sum(a: Int, b: Int) = a + b
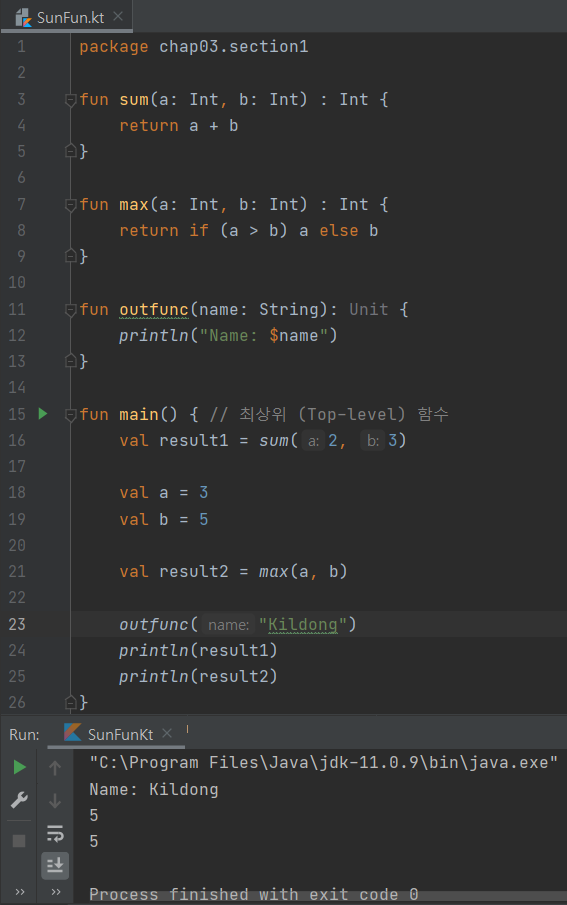
함수 실습
최상위 함수 특징 : sum이라는 이름은 main의 위 혹은 아래에 두더라도 해당 이름을 main 안에서 사용할 수 있다.
지역 함수는 실행 시키기 전에 정의해야 오류 없이 실행된다.
따라서, sum 함수가 result1보다 아래에 정의되면 오류가 발생한다.
max에서 사용하는 매개변수 a와 매개변수 b는 result2에서 보내는 인자 a와 b랑은 다른 것이다.
그래서 같은 이름이어도 한 파일에서 다른 함수에서 변수 값을 동일하게 지정하면 모두 잘 실행된다.
매개변수 a와 b는 인자 a와 b의 값을 복사한다고 생각하면 된다. 그리고 max 함수가 전부 실행되면 max 함수에서 사용하는 매개변수 a와 b는 사라진다.
Unit은 아무런 자료형을 지정하지 않았다는 의미이다. 특정 반환 타입을 없는 경우 사용한다. Unit은 생략 가능하다.
매개변수에 미리 default 값을 지정해두면 인자를 주지 않을 경우에도 오류없이 함수가 잘 실행된다.
여기서 만약, sum에 default 값을 지정해두지 않았다면 result2에 오류가 생긴다.
a와 b 중 한 개만 default 값을 지정해도 된다.
앞에 있는 매개변수 말고 뒤에 있는 매개변수에 값을 할당해주고 싶을 경우에는 "특정 매개변수 = 지정하고 싶은 값" 이런 식으로 해야한다. a에 값을 주고 싶을 경우에는 sum(3) 이렇게 해도 되지만, b에 값을 주고 싶을 경우에는 sum(b = 5) 이렇게 지정해주어야한다는 의미이다.
가변 인자 : 원하는 개수만큼 인자를 입력하고 싶을 경우 사용
가변 인자 함수 실습
인자가 1개든, 4개든 잘 실행됨을 확인할 수 있다.
이 함수는 생각보다 잘 사용하지 않기도 하고, 생각보다 잘 사용하기도 하는 것 같다.
기본적인 것을 만들 때에는 잘 사용되지 않지만, 가끔 이름을 주로 받고, 연락처는 필수가 아닐 경우 등 이러한 함수를 사용하기도 한다.
함수와 스택 프레임 이해하기 : 힙은 낮은 주소부터 높은 주소 순으로 쌓이고, 스택은 높은 주소부터 낮은 주소 순으로 프레임이 쌓임
main 함수의 프레임, 즉 지역 변수들, 항 (Operand) 스택, 상수 풀 등은 스택에 저장되고 동적 개체는 힙에 저장됨
프레임은 사용될 때 쌓였다고 실행이 완료되어 반환되면 사라짐.
수업에서 이야기하지 않았던 내용이 포함되었을 수 있습니다. 제가 공부하면서 좀 더 이해하기 쉽다고 느꼈던 내용들을 추가하여 작성하였음을 알려드립니다.
출처 : 코틀린 프로그래밍 기본 1/2 함수편 2-4 연산자를 조합해 다양한 식 만들기 (1) 기본연산자 참고자료
산술 연산자
출처 : 코틀린 프로그래밍 기본 1/2 함수편 2-4 연산자를 조합해 다양한 식 만들기 (1) 기본연산자 참고자료
대입 연산자
출처 : 코틀린 프로그래밍 기본 1/2 함수편 2-4 연산자를 조합해 다양한 식 만들기 (1) 기본연산자 참고자료
증가 연산자와 감소 연산자
출처 : 코틀린 프로그래밍 기본 1/2 함수편 2-4 연산자를 조합해 다양한 식 만들기 (1) 기본연산자 참고자료
변수 앞에 연산자를 붙이느냐, 뒤에 연산자를 붙이느냐에 따라 결과 값이 달라진다.
증가 연산자 실습
result1은 값이 증가된 후에 변수에 값이 할당되었기 때문에 1이 증가된 값이 출력되었고,
result2는 변수에 값이 할당된 후에 값이 증가되었기 때문에 b의 원래 값이 출력되었다.
변수 a와 b는 증가 연산자에 의해 모두 값이 증가되었다.
처음에 이걸 학습할 때는 헷갈릴 수 있는데, 앞에서부터 계산한다고 생각하면 좀 더 빠르게 이해할 수 있다.
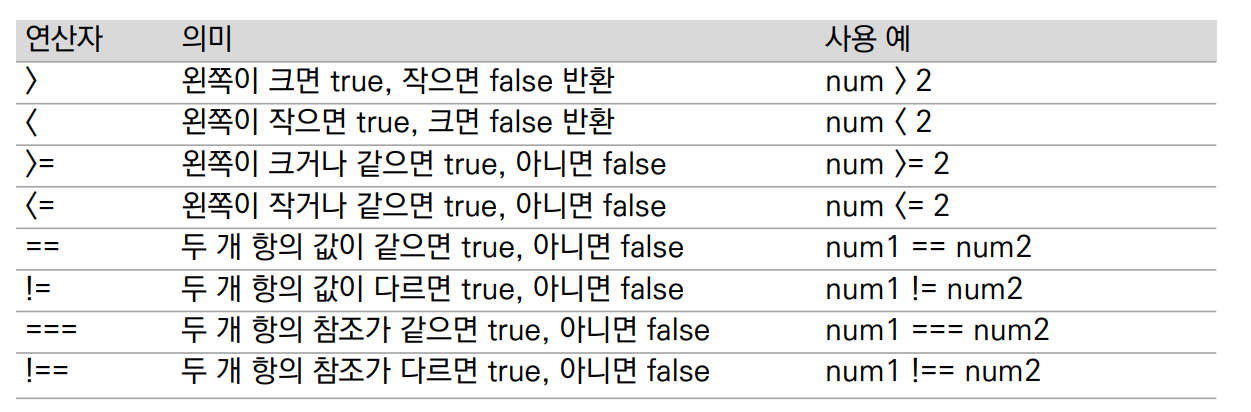
비교 연산자
논리 연산자
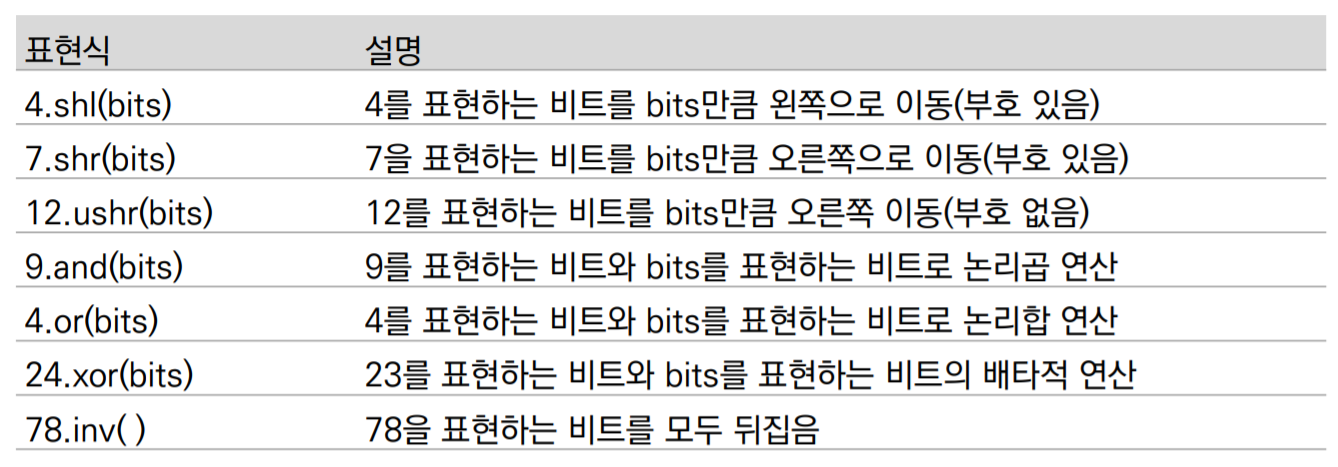
비트 연산자 : 2진법 체계를 다루기 위한 연산자
(사족) 비트 연산자를 주로 코딩할 때 많이 사용하지는 않지만 가끔 사용하는 경우도 있었다. 그래서 외워둘 필요까지는 없을 수 있지만, 표현식과 설명을 연결할 수 있고, 어떤 식으로 작동되는지 안다면 나중에 필요할 때 편하게 사용할 수 있을 것이라고 생각한다. (전공하면서 느낀점 - 프로젝트할 때 가끔 사용한 적 있음)
비트 연산자 실습
x는 10진수로 4이고, y는 10진수로 5, z는 10진수로 15인 값이다.
shl은 괄호만큼 왼쪽으로 비트를 이동하는 것으로, 0b0000_0100에서 2bit 움직인 0b0001_0000으로 16이 출력된다.
inv는 표현하는 비트를 완전히 뒤집는 것으로, 0b0000_0100을 뒤집어 0b1111_1011이 되어 -5가 된다.
개인적으로 비트 연산자를 계산할 때는 8진수, 16진수 등보다 2진수로 바꾸어서 계산하는 것이 편하다고 생각한다.